在实际的系统开发中,当流量增大时,通常会使用缓存技术去减少数据库的访问来减少数据库的压力。而随着流量越来越大,缓存的量也就越来越大,这时也会引用到分布式缓存。
分布式缓存
所谓的分布式缓存就是用一堆机器构成一个大的缓存池,每一台机器缓存一部分数据,这样也能达到水平伸缩的效果。比如说一台机器能够支撑20G的数据缓存,需要支撑100G,则可以使用5台机器。举个例子,假如用户登录系统后需要把用户的信息放入到缓存中,系统的行为如下:
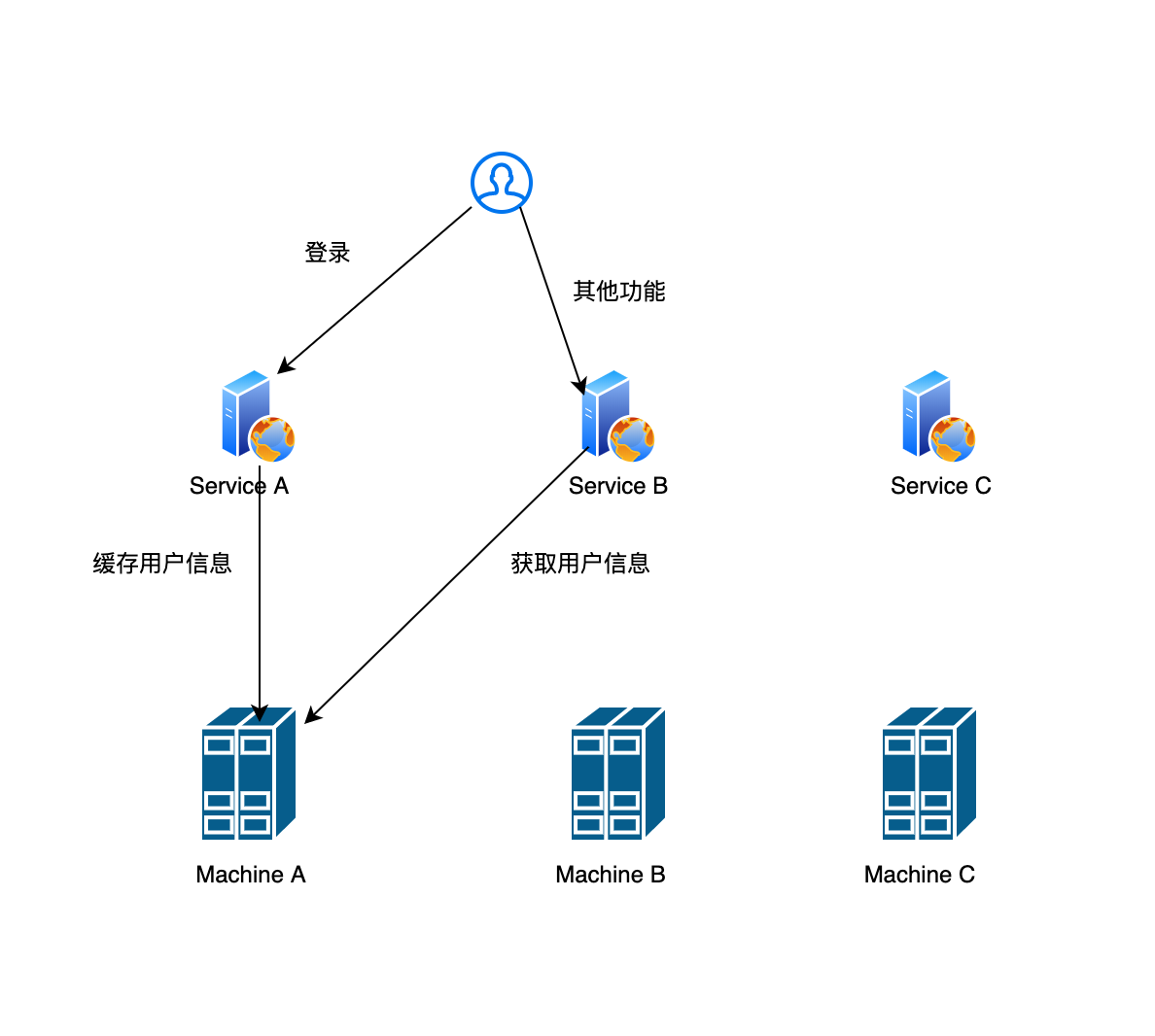
在服务A 中,用户登录了,并且把用户信息缓存到缓存机器A中,用户登录后访问服务B时,服务B就可以拿到用户的缓存信息。
这里的问题是:service A 怎么选择存放用户的缓存信息,service B 怎么知道某个用户的缓存信息存放在哪个缓存机器。最简单的策略就是随机查询一个缓存机器,但是这个策略有两个问题:
- 很容易就会导致缓存没有命中,毕竟是随机的。
- 缓存数据会在多台机器上重复存放
这时只要做到同一个数据来源,能够保证访问的是同一台机器,这样就可以解决上面的问题。最简单的方式就是对访问的数据进行hash,然后对机器进行编号(0到N-1),最后对可用的机器数量进行取模。上面的例子中,如果对用户的id做hash。这时后,只要你的缓存机器不变动,增加或减少,就能够分布式缓存了。
i = Hash(key) % N (N为可用机器数量)
一旦你缓存机器变动了,就会引起大规模的缓存命中失败,hash(key) % (N-1),hash(key) % (N+1),减一台或者加一台,就会有大量的缓存丢失了。
这种做法导致了系统的容错性(出错后的可用情况)和扩展性(增加机器后服务能力是否可以提高)变得很差。一致性hansh就是为了解决这个问题的。
一致性哈希
一致性哈希方法如下图:
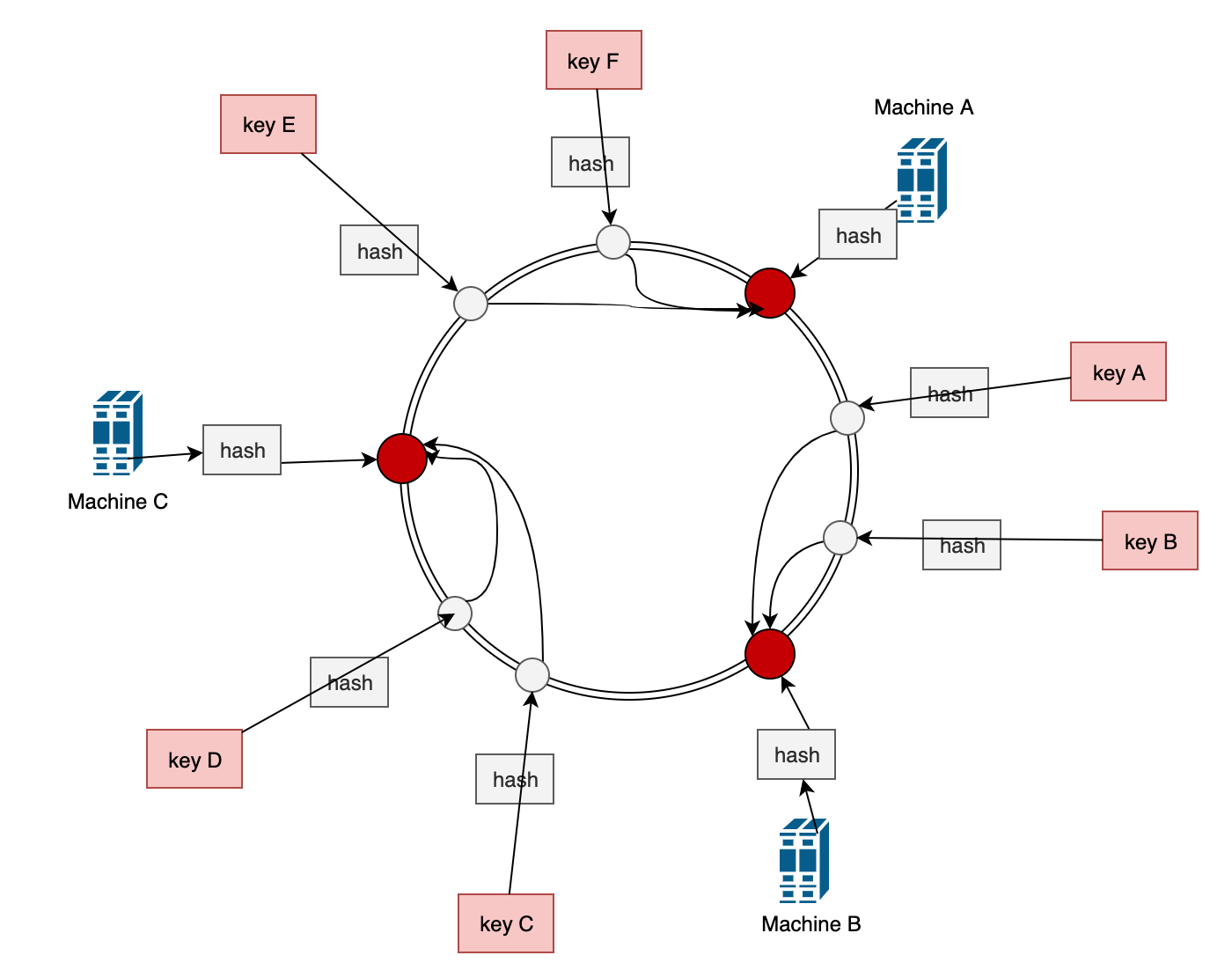
一致性hash将整个哈希值空间组织成一个虚拟的圆环,它的值空间为0-2^32-1(32位无符号整型),整个空间按顺时针组织,0和2^32-1在零点重合。它首先对缓存节点的机器进行hash (一般是ip或主机名)计算,将hash 值落到圆环上。
每当有key 要存储的时候,按照同样的哈希算法求得hash 值并落到圆环上,以此位置起点顺时针方向找到第一台缓存机器,则为该key 存放的节点。
容错性和扩展性
假设现在机器A 宕机了,受影响的也就只有E和F,被重新定向到机器B。
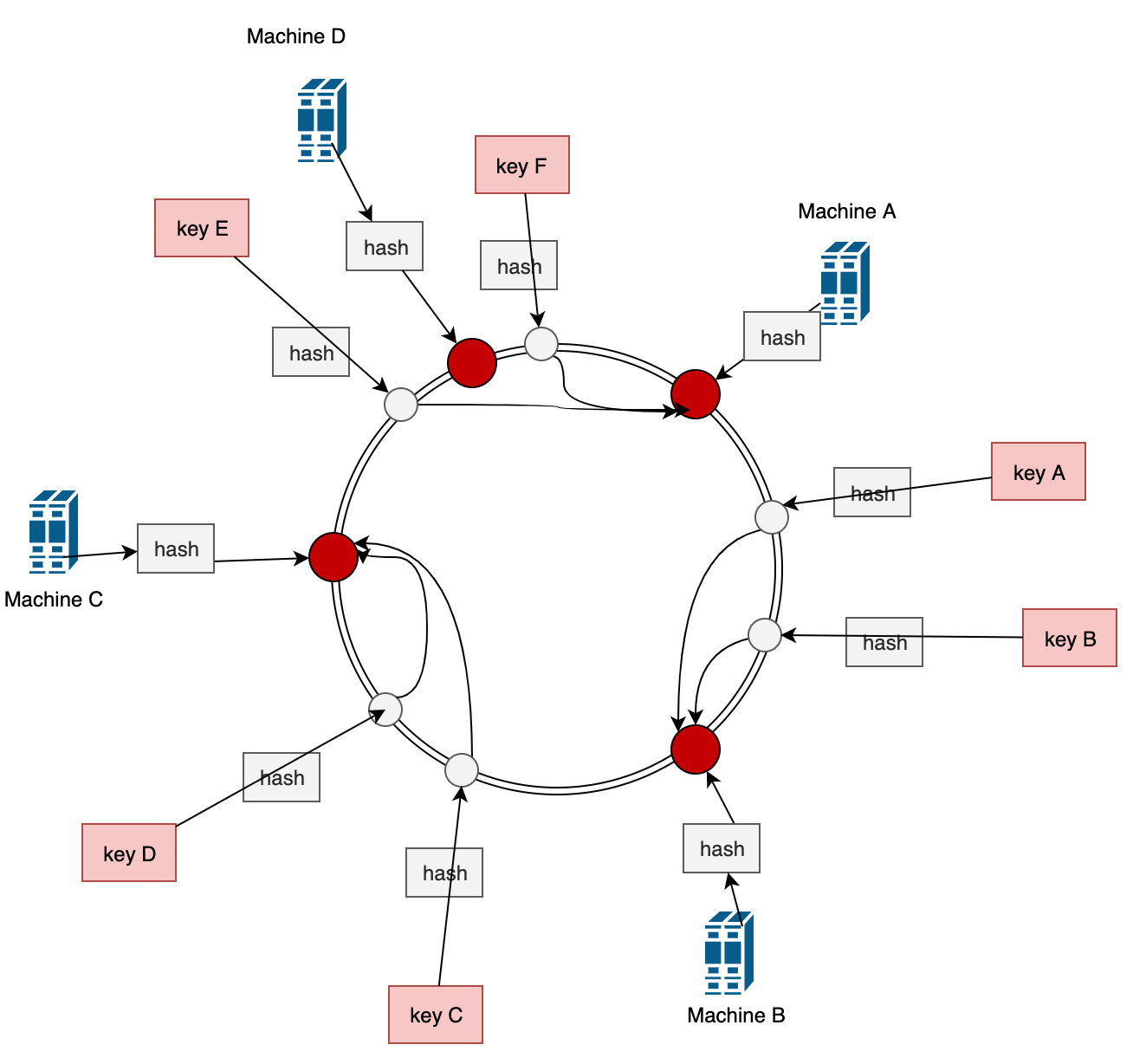
假设现在流量继续上升,增加了一台机器D,受影响的也就只有E, 被重定向到机器D上去。例如上图
所以,无论是增加机器还是删除机器,最终影响的都只是部分数据。
虚节点
有一致性哈希有对机器进行hash,然后落在圆环上,当机器比较少的时候,会出现机器分布不均匀的情况,导致部分机器分布的数据很少,大部分落在另外的机器上。例如下面
在虚拟节点下,一个机器可以分成100-200个节点,这样一台机器就有很多个虚拟节点分布在圆环上,最终指向同一个机器,这样就可以保证节点均匀分布。
譬如,对机器A 划分两百个虚拟节点,可以对“machineA#1”,”machineA#2”…”machineA#200”这样生成hash值并分配到圆环上。只要使用同样的hash 算法,中间只是增加了一个映射到真实节点的过程。
hash 算法
参考spymemcached中用到的hash 算法有以下几种
- NATIVE_HASH
- CRC_HASH
- FNV1_64_HASH
- FNV1A_64_HASH
- FNV1_32_HASH
- FNV1A_32_HASH
- KETAMA_HASH
我们这里看一下KETAMA_HASH
How it works
- Take your list of servers (eg: 1.2.3.4:11211, 5.6.7.8:11211, 9.8.7.6:11211)
- Hash each server string to several (100-200) unsigned ints
- Conceptually, these numbers are placed on a circle called the continuum. (imagine a clock face that goes from 0 to 2^32)
- Each number links to the server it was hashed from, so servers appear at several points on the continuum, by each of the numbers they hashed to.
- To map a key->server, hash your key to a single unsigned int, and find the next biggest number on the continuum. The server linked to that number is the correct server for that key.
- If you hash your key to a value near 2^32 and there are no points on the continuum greater than your hash, return the first server in the continuum.
简单来说就是把缓存的机器做100-200次hash,最后这些hash 值都会落在圆环上,每一个hash 值都会记录它的真实机器。对于要操作的key,使用同样的hash 方式,根据hash 值找到在圆环上跟它最接近的上界,就是要操作的节点(就是一个ceil 方式),如果你的hash 值在2^32附近找不到节点,则把第一个作为它的操作节点。
这么一看跟我们上面说的就没啥区别了,这里主要是看看它的hash ketama算法。
在spymemcached 中提供了两种内置的算法来查找机器的位置,它们都实现了NodeLocator,分别是:
- 缓存机器取模法:
ArrayModNodeLocator - 一致性哈希算法:
KetamaNodeLocator
代码实现
protected void setKetamaNodes(List<MemcachedNode> nodes) {
TreeMap<Long, MemcachedNode> newNodeMap =
new TreeMap<Long, MemcachedNode>();
int numReps = config.getNodeRepetitions();
int nodeCount = nodes.size();
int totalWeight = 0;
if (isWeightedKetama) {
for (MemcachedNode node : nodes) {
totalWeight += weights.get(node.getSocketAddress());
}
}
for (MemcachedNode node : nodes) {
if (isWeightedKetama) {
int thisWeight = weights.get(node.getSocketAddress());
float percent = (float)thisWeight / (float)totalWeight;
int pointerPerServer = (int)((Math.floor((float)(percent * (float)config.getNodeRepetitions() / 4 * (float)nodeCount + 0.0000000001))) * 4);
for (int i = 0; i < pointerPerServer / 4; i++) {
for(long position : ketamaNodePositionsAtIteration(node, i)) {
newNodeMap.put(position, node);
getLogger().debug("Adding node %s with weight %s in position %d", node, thisWeight, position);
}
}
} else {
// Ketama does some special work with md5 where it reuses chunks.
// Check to be backwards compatible, the hash algorithm does not
// matter for Ketama, just the placement should always be done using
// MD5
if (hashAlg == DefaultHashAlgorithm.KETAMA_HASH) {
for (int i = 0; i < numReps / 4; i++) {
for(long position : ketamaNodePositionsAtIteration(node, i)) {
newNodeMap.put(position, node);
getLogger().debug("Adding node %s in position %d", node, position);
}
}
} else {
for (int i = 0; i < numReps; i++) {
newNodeMap.put(hashAlg.hash(config.getKeyForNode(node, i)), node);
}
}
}
}
assert newNodeMap.size() == numReps * nodes.size();
ketamaNodes = newNodeMap;
}
private List<Long> ketamaNodePositionsAtIteration(MemcachedNode node, int iteration) {
List<Long> positions = new ArrayList<Long>();
byte[] digest = DefaultHashAlgorithm.computeMd5(config.getKeyForNode(node, iteration));
for (int h = 0; h < 4; h++) {
Long k = ((long) (digest[3 + h * 4] & 0xFF) << 24)
| ((long) (digest[2 + h * 4] & 0xFF) << 16)
| ((long) (digest[1 + h * 4] & 0xFF) << 8)
| (digest[h * 4] & 0xFF);
positions.add(k);
}
return positions;
}
来看看具体的实现方法setKetamaNodes(List<MemcachedNode> nodes)首先这里的MemcachedNode就是真实的缓存机器,它里面封装了很多东西,包括操作,连接等等。TreeMap用来模拟圆环,它是一个红黑树的一个实现,里面的节点都是有序的。
int numReps = config.getNodeRepetitions();
这里首先获取配置,表示每一个节点要做多少次hash,也就是生成多少个虚拟节点,默认是160个。
这里有两种不同的处理,一个是在有配置权重后,首先计算真实节点的总权重,然后根据真实节点的权重占比计算出虚拟节点的占比(也就是数量)。在ketamaNodePositionsAtIteration(MemcachedNode node, int iteration) 的
config.getKeyForNode(node, iteration)
会生成一个key 类似127.0.0.1:11311-0。然后通过MD5生成这个key的摘要,因为MD5后的摘要是16位,这里是通过每4位一组,使用位移运算生成一个32位的整数,作为一个虚拟节点,这样就每一个key 会有四个,然后在根据上面的逻辑,比如非权重的,就会有 numReps/4 * 4 就有160 个虚拟节点了。
所以以上整个初始化过程是比较简单的实现,ketama 算法就是通过MD5做分组来生成虚拟节点。
现在看看获取时候的代码实现:
public MemcachedNode getPrimary(final String k) {
MemcachedNode rv = getNodeForKey(hashAlg.hash(k));
assert rv != null : "Found no node for key " + k;
return rv;
}
MemcachedNode getNodeForKey(long hash) {
final MemcachedNode rv;
if (!ketamaNodes.containsKey(hash)) {
// Java 1.6 adds a ceilingKey method, but I'm still stuck in 1.5
// in a lot of places, so I'm doing this myself.
SortedMap<Long, MemcachedNode> tailMap = getKetamaNodes().tailMap(hash);
if (tailMap.isEmpty()) {
hash = getKetamaNodes().firstKey();
} else {
hash = tailMap.firstKey();
}
}
rv = getKetamaNodes().get(hash);
return rv;
}
首先 getPrimary(final String k) 中根据算法对key 进行hash,然后使用该hash值去圆环中查找。因为是通过SortedMap去模拟圆环,所有通过tailMap就可以获取到比该hash 值要大的数(如果在JDK1.6 中则可以直接通过 ceilingKey就可以获取了),如果存在则取第一个,如果不存在,则取整个圆环第一个。
以上就是ketama 算法的具体实现。